
Data Archiving is something everyone does, whether you mean too or not. Think about you smart devices, you may use them to take pictures, send e-mail, write lists, or even make calls (Say what!). The history, or more specifically, logs about what you do may be saved in a few places. The question to ask is are you using a google account, apple account, or samsung?
Most activities create events, and even a log associated with that data. Say you create some code and push this to a Git Repo, well you have the data itself, the revision, and the metadata that is associated with the revision. Ultimately you have been part of the archiving process. The old code is classified and still available.
Lets take a different look at this now, think about a business or organisation managing data. Part of the process is to take a backup and that backup could be file level, or Block level depending on the type of backup being performed and why. Once this data is created we have some considerations, these are:-
- Who has access to the data?
- What processes or people have access to the information, and how often will this data be accessed?
- How long should the data be stored?
- This could be seconds to years depending on the type of information and what the use for this data is. If code, company secrets, or contracts, then this could be for years. Other data may also be susceptible to regulation like GDPR.
- When should the data be released/deleted/removed?
- After setting a policy for how long data is valid, it must be deleted or removed. This is essential, not only to remain compliant with policies and regulations, but attackers cannot steal what does not exist.
- How is the data protected at rest?
- What is the overall method for encrypting the data? What sort of polices are set around the organisations encryption? What secret materials do you need to also take care of and archive? If data is ciphered, then the key has to be available for as long as the data it is stored. This now brings into play the archiving of cryptographic materials… (not in this post though!)
- How many copies of the data are there?
- Having a single backup of data that is archived is generally not looked at as good practice. However one backup is better than no backups.
- Incremental, Differential, or Full
- How will you discover the data in future?
- Classification
- Tagging
- How do you maintain the integrity of the data?
- Hashing
- Legal Hold and Read Only
- What will you do if the data is required in future?
- Restoration
- Legal Holds
- Read-Only access
- How is the data deleted?
- Secure deletion methods
That list in non-exhaustive, but certainly gets you thinking about the strategies in place.
From a security perspective, data backups and data archiving are a key part of business continuity, disaster recovery, legal discovery, and recovery from Cyber Attacks. However it has been seen that businesses backup strategies fail, and it is only when they are needed most that any short comings are identified.
There are some simple principles that can help with avoiding such a gap being exploited or identified win this way. Using the initials A.I.C. help with this (Availability, Integrity, and Confidentiality). The thing you will note in the following list is that you probably think of some of these same things when considering your own data (Family Photos, Tax Returns, etc.)
- Availability
- How many Copies are being taken, and where are those copies stored?
- Run Restoration exercises to see if your predicted recovery objectives can be met.
- Verify there is a good process for obtaining the data with a set of authorisers or data custodians.
- Classification of data to identify the value to the business and assist with discovery when deciding what to restore.
- Integrity
- Is there a hash to identify the data’s state at back up?
- Were there errors when taking the backup, and when did they occur?
- Classification of data should be used to identify whether the data archived can be changed
- Confidentiality
- Who and what is authorised to make a backup or change?
- Is your data encrypted, and are you able to get access to the key materials when necessary?
- What is the classification of the data? (Is it secret, private or public?)
You can think of availability with the principle of 3-2-1. This assumes that when a backup is created, you are making 3 copies of the data, securing it in 2 locations that are convenient for restoration, and 1 that is secured at a cold site where access is typically out off band.
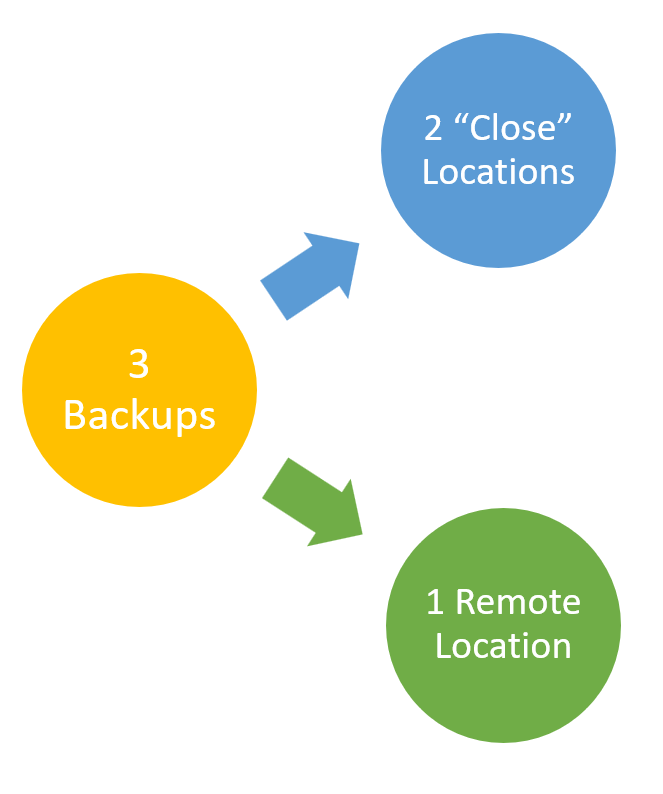
You would consider the offsite backups to be Full data sets, though in practice incrementals and differentials can also be sent out of band. This is normally based on the size of the data set, as this can have an impact on the overall time it takes to backup.
I have touched on a few subjects in this blog post and I think I will need to write another to go into this in more detail
